Krzysztof Włodarczyk
Budowanie zapytania wyszukiwawczego w naukowych bazach danych. Podstawy strategii
Publikacja ma na celu wprowadzenie do zagadnienia strategii budowania zapytania wyszukiwawczego w naukowych bazach danych. Zaprezentowana została strategia wyszukiwania, rozumiana jako całość działań podejmowanych od momentu zaistnienia potrzeby informacyjnej do chwili jej zaspokojenia. Przedstawiono wyszukiwanie na podstawie słów języka naturalnego oraz języka haseł przedmiotowych, wraz z omówieniem plusów i minusów poszczególnych rozwiązań. Tekst ma charakter poradnika, adresowanego głównie do osób rozpoczynających pisanie przeglądów systematycznych i praktykowanie zasad medycyny opartej na faktach.
Jak podaje Encyklopedia Britannica, baza danych to zbiór danych lub informacji zbudowany w sposób umożliwiający jego szybkie przeszukanie za pomocą komputera. Baza charakteryzuje się strukturą ułatwiającą przechowywanie, przeszukiwanie, modyfikację i usuwanie informacji za pomocą różnych operacji, określanych mianem przetwarzania danych. Plik lub pliki zawarte w bazie danych mogą zostać podzielone na rekordy, z których każdy składa się z jednego albo kilku pól. Pola są podstawowymi jednostkami w zbiorze danych. Użytkownicy wyszukują informacje głównie poprzez formułowanie zapytań. Używając słów kluczowych i sortujących komend, mogą szybko przeszukiwać, zmieniać, grupować i wybierać pola rekordów, aby znaleźć lub utworzyć raport zagregowanych informacji według reguł zarządzania danymi systemu operacyjnego danej bazy.
Bazy danych różnią się między sobą głównie zawartością. Jednym ze sposobów klasyfikacji baz jest podział ze względu na rodzaj danych stanowiących ich zawartość – na tej podstawie wyodrębnia się bazy bibliograficzne, pełnotekstowe i faktograficzne. Obecne tempo rozwoju baz naukowych sprawia, że różnice się zacierają, jednak nawet bazy tego samego rodzaju mają odmienną zawartość (np. zakres uwzględnionych czasopism), strukturę poszczególnych rekordów i narzędzia wyszukiwawcze. Te ostatnie, chociaż różniące się od siebie, opierają się na kilku sprawdzonych pomysłach, więc zrozumienie ogólnej idei pozwala odnaleźć się w większości systemów. W dalszej części tekstu omówiono dwie największe bazy bibliograficzne: PubMed oraz Embase, a także bazę faktograficzną The Cochrane Library. Są one kluczowymi, niezbędnymi źródłami informacji naukowej i wiedzy w zakresie nauk biomedycznych i farmakologicznych oraz zdrowia publicznego.
Czym są PubMed, Embase i The Cochrane Library?
- PubMed jest bibliograficzną bazą danych wydawaną przez United States National Library of Medicine (NLM). Zawiera bibliograficzne rekordy publikacji ukazujących się w ponad 5500 czasopismach naukowych. Zdecydowana większość rekordów zaopatrzona jest w abstrakt i odnośnik do pełnego tekstu na stronie wydawcy lub do otwartego repozytorium PubMed Central. Baza indeksuje głównie publikacje w języku angielskim.
- Embase jest bibliograficzną bazą danych wydawaną przez Elsevier. Zawiera bibliograficzne rekordy publikacji z ponad 7000 naukowych czasopism biomedycznych i farmakologicznych. System wyszukiwania uwzględnia możliwość budowania złożonych zapytań z uwzględnieniem nazw leków, wraz z uszczegółowieniem kontekstu wyszukiwania (np. toksyczności dla wątroby). Profil indeksowanych czasopism jest bardziej międzynarodowy (można powiedzieć, że eurocentryczny) niż w przypadku PubMedu. Zasoby obu tych baz pokrywają się w około 60%.
- The Cochrane Library to zbiór siedmiu baz danych, z których sześć stanowi wysokiej jakości źródło informacji opartych na dowodach naukowych (EBM). Wydawcą jest międzynarodowa organizacja Cochrane Collaboration, skupiająca szerokie grono badaczy i specjalistów. Na szczególną uwagę zasługuje baza Cochrane Database of Systematic Reviews, zawierająca prawie 10 000 systematycznych przeglądów badań medycznych.
Proste wyszukiwanie na podstawie bazy PubMed
Budowanie zapytania wyszukiwawczego najłatwiej zacząć od słowa w języku naturalnym. Po wpisaniu wybranego terminu w okno wyszukiwarki zapytanie zostanie przetworzone przez system, a wyniki wyszukiwania będą się składać z rekordów, w których polach odnaleziono wskazaną frazę. Niestety, w takich przypadkach najczęściej zostanie wygenerowana duża liczba wyników, a w dodatku mogą się one okazać mało relatywne. Spowodowane jest to działaniem samego mechanizmu wyszukiwania – wystarczy, że wyszukiwana fraza wystąpi gdziekolwiek w rekordzie (np. w tytule publikacji albo w abstrakcie), aby rekord został uznany za odpowiedź na zapytanie użytkownika.

Wyszukiwanie fasetowe. Stosowanie ograniczników w bazie PubMed
Ze względu na bardzo dużą liczbę otrzymanych wyników wyszukiwania (przykład prezentuje stan z dnia 01.07.2017 r.) niezbędne okazuje się ich ograniczenie. Jedną z możliwości jest zastosowanie faset, które odwołują się do różnych atrybutów publikacji. Taką opcję oferuje większość naukowych baz danych, a lista ograniczników znajduje się przeważnie po lewej stronie ekranu. PubMed domyślnie pokazuje jedynie podstawowe ograniczniki. W celu dodania możliwości wyboru innych należy posłużyć się opcją Show additional filters. Za pomocą faset można m.in.:
- ograniczyć wyniki wyszukiwania do wybranego rodzaju (lub rodzajów) prac,
- ograniczyć wyświetlanie do rekordów, które mają dostępny bezpłatny pełen tekst,
- ograniczyć zakres lat, z których podchodzą publikacje (np. do ostatniego pięciolecia),
- ograniczyć wiek (np. publikacje tylko o dzieciach),
- ograniczyć płeć (np. wyłącznie kobiety),
- ograniczyć wyniki wyszukiwania do publikacji w wybranym języku.
Przykładowy problem: Potrzeba znaleźć prace z ostatnich 5 lat będące przeglądami systematycznymi na temat gruźlicy u dzieci, z bezpłatnym dostępem do pełnej treści, po angielsku. Za pomocą samych faset (il. 2) można w ten sposób ograniczyć listę ponad 230 000 rekordów do 56 publikacji.

- Podany przykład uwzględnia wyniki ograniczone do rekordów, w których znajduje się odnośnik do bezpłatnie dostępnej pełnej treści publikacji (Open Access). Pominięte zostały informacje o publikacjach, do których dostęp jest płatny. Biblioteki akademickie i jednostki naukowe zazwyczaj mają wykupiony dostęp do wielu czasopism naukowych, nie musi się on jednak pokrywać z odnośnikiem do pełnej treści publikacji dostępnym w rekordzie PubMed. Zawsze warto jeszcze sprawdzić dostęp za pomocą narzędzi oferowanych przez bibliotekę.
- Nie warto używać wszystkich metod ograniczania liczby wyników jednocześnie. Dobrze jest stosować ograniczenia lub dodawać kolejne hasła pojedynczo. W ten sposób łatwiej zaobserwować, jakie efekty przynoszą poszczególne elementy zapytania.
- Przy zawężaniu zapytania wyszukiwawczego trzeba zachować zdrowy rozsądek. Ograniczenie liczby uzyskanych wyników do minimum może spowodować, że pominięte zostaną wartościowe publikacje.
- Należy zwrócić uwagę na różnice między amerykańskim a brytyjskim zapisem niektórych terminów medycznych – pedratic a paediatric, hemoglobin a haemoglobin, glycemic index a glycaemic index etc.
Korzystanie z kontrolowanego słownika haseł przedmiotowych MeSH
Minusem wyszukiwania za pomocą słów w języku naturalnym jest konieczność uwzględnienia w zapytaniu wielu synonimów (oraz form gramatycznych!), ponieważ autorzy publikacji mogą używać różnych słów do opisania tej samej jednostki chorobowej (czy innego zagadnienia biomedycznego). Alternatywą jest korzystanie z języka haseł przedmiotowych (JHP). Hasła przedmiotowe nadawane są przez specjalistów, którzy po zapoznaniu się z treścią publikacji opisują ją za pomocą terminów z kontrolowanego słownika, właściwego dla danej bazy. Obowiązkiem osoby opracowującej publikację jest przydzielenie do niej tylu haseł, ilu potrzeba, aby objąć wszystkie istotne kwestie omówione w dokumencie. Dodatkowo hasła dzieli się na pierwszorzędne i drugorzędne, w zależności od nacisku, jaki położono w publikacji na daną kwestię. Warto też wiedzieć, że hasła przedmiotowe tworzą pewną hierarchię, którą można określić mianem drzewa. Najogólniejsze hasła (pień) rozdzielają się na bardziej szczegółowe (konary), a te – na dalsze, coraz bardziej konkretne (gałęzie).
PubMed korzysta ze słownika MeSH (Medical Subject Headings), rozwijanego przez wspomnianą wcześniej National Medical Library. Hasła odpowiadają terminom biomedycznym i ułożone są w hierarchicznym porządku. Dostęp do słownika można uzyskać na stronie PubMed (MeSH Database).
Przykład: publikacja może być opisana za pomocą hasła preoperative care, intraoperative care lub postoperative care, w zależności od tego, której fazy opieki nad pacjentem dotyczy. Dla wszystkich trzech haseł nadrzędne jest hasło perioperative care. Zapytanie zbudowane z hasła nadrzędnego poskutkuje znalezieniem publikacji opisanych za pomocą haseł podrzędnych. Idąc dalej, perioperative care jest podrzędne wobec dwóch innych haseł: patient care oraz surgical procedures.

- Uwzględnianie w wyniku wyszukiwania haseł przedmiotowych podrzędnych względem hasła użytego w zapytaniu można wyłączyć. Służy do tego widoczna na karcie hasła przedmiotowego opcja Do not include MeSH terms found below this term in the MeSH hierarchy. Funkcja uwzględniania haseł niższego rzędu nazywa się Explode Tree.
- Warto zauważyć, że hasło przedmiotowe może znajdować się w więcej niż jednym drzewie (polihierarchia).
Zapytanie zbudowane na podstawie haseł przedmiotowych pozwala na ograniczenie wyników do rekordów bardziej dopasowanych do tematu wyszukiwania. Dzieje się tak, ponieważ – jak wyjaśniono wyżej – wynik wyszukiwania zawiera wówczas wyłącznie publikacje opisane przez specjalistów za pomocą podanych haseł. Pominięte zostają publikacje, w których dane słowo w języku naturalnym miałoby trzeciorzędne znaczenie w stosunku do głównego tematu lub pojawiłoby się przy okazji. Jednocześnie otrzymany wynik obejmuje publikacje, których rekord nie zawierałby pola ze słowem, za jakiego pomocą byłoby przeprowadzane wyszukiwanie na podstawie języka naturalnego.
- Karta hasła przedmiotowego zawiera informację o synonimach i różnych formach zapisu terminu, które są uwzględniane przy użyciu danego hasła w czasie przeszukiwania bazy. Przykładowo tuberculosis zastępuje: tuberculoses, Kochs disease, Koch’s disease, Koch disease etc. Rozwiązanie to ogranicza problem wynikający z bogactwa terminologii oraz eliminuje konieczność uwzględniania wariantów ortograficznych czy gramatycznych.
- Po uzyskaniu pierwszych wyników zapytania wyszukiwawczego warto sprawdzić w poszczególnych rekordach, jakie inne hasła przedmiotowe zostały wykorzystane do ich opisania. W ten sposób możliwe jest poznanie haseł, które lepiej odpowiadają poszukiwanej treści.
- Stosowanie haseł przedmiotowych ma jednakże jeden minus: pomijane są nowe publikacje obecne w bazie, do których specjaliści nie zdążyli jeszcze przyporządkować odpowiednich haseł.
Przykładowy problem: Potrzeba znaleźć prace dotyczące negatywnych efektów szczepień przeciw grypie u osób z alergią na jaja. Karta hasła przedmiotowego zaopatrzona jest w wygodne narzędzie do budowania zapytania wyszukiwawczego (PubMed Search Builder). Do konstruktora można dodać hasło z aktualnie otwartej karty (w tym przykładzie: influenza vaccines). Możliwe jest także uszczegółowienie danego hasła – wystarczy wybrać odpowiedni konspekt (w tym przykładzie: adverse effects).

Następnie należy dodać drugie hasło przedmiotowe. Budowane zapytania wyszukiwawczego nie zostanie przerwane po przejściu do kolejnego hasła w słowniku, dzięki czemu można w wygodny sposób rozszerzyć zapytanie o kolejne tematy. Warto zauważyć, że słownik podpowiada właściwe hasło – dla alergii na jaja jest nim egg hypersensitivity.
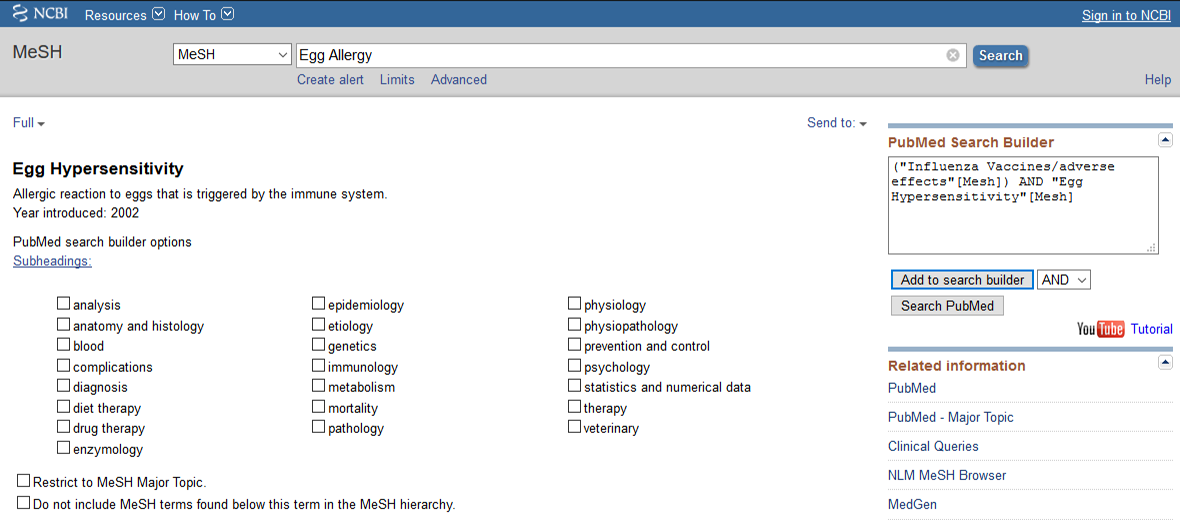
Operatory logiczne Boole’a
Operatory logiczne AND, OR i NOT zostały pomyślane przez XIX-wiecznego brytyjskiego matematyka George’a Boole’a. Sugerował on, że zdania logiczne mogą być wyrażane podobnie jak algebra. Operatory służą do łączenia słów – zarówno języka naturalnego, jak i haseł przedmiotowych – w celu osiągnięcia optymalnych wyników wyszukiwania.
- Najprostszym operatorem jest AND, używany już domyślnie we wcześniejszych przykładach. Służy on do łączenia dwóch fraz w taki sposób, aby wyświetlone zostały rekordy, które zawierają oba wyrażenia. Bardzo często wpisanie AND w okno wyszukiwania nie jest wymagane, ponieważ bazy domyślnie łączą wprowadzone słowa tym operatorem logicznym. Przykład: Crohn’s disease AND perioperative care.
- Inaczej jest w przypadku operatora OR, który powoduje wyszukanie rekordów zawierających przynajmniej jedną z podanych fraz. Przydatne może się okazać używanie nawiasów. Przykład: common cold AND (vitamin c OR zinc).
- Za pomocą operatora NOT można wykluczyć konkretną frazę. Dzięki temu wygenerowana lista nie będzie zawierała rekordów ze wskazanym terminem, co pozwoli znacznie ograniczyć liczbę wyników. Przykład: latex gloves NOT allergy.
Zarządzanie wynikami wyszukiwania na podstawie bazy PubMed
Przygotowane wyniki można zachować na wiele sposobów. Polecenie Send to pozwala m.in. zapisać je do pliku, przesłać na adres poczty elektronicznej czy dodać do managera cytowań (np. do programu EndNote). Po założeniu indywidualnego konta możliwe staje się gromadzenie prac bezpośrednio w systemie (My Bibliography). Zorganizowaną w ten sposób listę publikacji łatwo udostępnić innym za pomocą linku.

- Założenie bezpłatnego konta umożliwia także zapisanie całego zapytania wyszukiwawczego i tworzenie na jego podstawie powiadomień. Po utworzeniu powiadomienia na podany przy rejestracji adres poczty elektronicznej będą przesyłane wiadomości informujące o nowych publikacjach, które spełniają warunki zapisanego zapytania. Częstotliwość przychodzenia powiadomień można dowolnie ustalić, indywidualnie dla każdego zapytania wyszukiwawczego.
Embase, dodatkowe fasety oraz Emtree
Embase korzysta z własnego słownika haseł przedmiotowych – Emtree. Bazuje on w znacznej mierze na MeSH, ale główny nacisk został położony na farmakologię i nazwy leków. Liczba deskryptorów dotyczących substancji chemicznych w Emtree przewyższa liczbę wszystkich deskryptorów w MeSH. Leki można wyszukiwać przez nazwy rodzajowe, handlowe i chemiczne oraz kody laboratoryjne. Poniżej znajduje się przykład wykorzystania nazw leku na podstawie karty hasła przedmiotowego Isoniazid (fragment).

Nawigacja fasetowa w Embase jest bardzo podobna do tej stosowanej w bazie PubMed. Ze względu na ukierunkowanie słownika Emtree na farmakologię za pomocą faset można ograniczać wyniki wyszukiwania na podstawie nazw leków (Drugs), nazw handlowych (Drug Trade Names) czy nawet producentów leków (Drug Manufacturers). Na szczególną uwagę zasługuje możliwość wykorzystania ograniczników do zawężenia kontekstu, w jakim wyniki wyszukiwania mają obejmować informacje o danym leku.
Przykładowy problem: Potrzeba znaleźć informacje o toksyczności dla wątroby leku Isoniazid w leczeniu gruźlicy. Podobnie jak w przypadku MeSH, karty haseł przedmiotowych w Emtree zaopatrzone są w wygodne narzędzie do budowania zapytań. Na potrzeby tego zadania wykonane zostało wyszukiwanie na podstawie hasła tuberculosis. Otrzymane wyniki – 236 088 publikacji – zostały następnie ograniczone za pomocą deskryptora isoniazid, w ujęciu efektów ubocznych (adverse drug reaction), z uszczegółowieniem do toksyczności (liver toxicity). Na każdym etapie ograniczania obok deskryptora widoczna jest liczba publikacji, które będą stanowiły wynik wyszukiwania.

The Cochrane Library i przeglądy systematyczne
Cochrane Library składa się z siedmiu baz, z których na szczególną uwagę zasługuje The Cochrane Database of Systematic Reviews. Zawiera ona opracowane przez specjalistów (Cochrane Review Groups) pełnotekstowe przeglądy badań dotyczące efektów interwencji medycznych w opiece zdrowotnej. Pozostałe bazy zawierają m.in. streszczenia przeglądów systematycznych na temat efektywności postępowania w ochronie zdrowia, raporty z medycznych badań kontrolowanych, rejestr publikacji poświęconych metodom prowadzenia badań, analizy stosowania technologii zdrowotnych czy opracowania ekonomiczne związane z ochroną zdrowia. Ostatnia, siódma baza zawiera informacje o organizacji Cochrane i o grupach specjalistów odpowiadających za tworzenie i aktualizację ww. przeglądów.
Wyszukiwanie warto rozpocząć od prostego zapytania w języku naturalnym lub za pomocą hasła MeSH. Cochrane Library zawiera ok. 10 000 przeglądów systematycznych (stan na 01.07.2017). Nie jest to tak wiele rekordów, jak w przypadku baz PubMed i Embase – dlatego warto najpierw zorientować się w zawartości bazy, bo może się okazać, że budowanie złożonego zapytania w ogóle nie będzie konieczne.

- Proste wyszukiwanie za pomocą hasła w języku naturalnym influenza vaccines wskazało na 26 przeglądów systematycznych. Wyszukiwanie za pomocą tego samego terminu, ale w języku haseł przedmiotowych MeSH zwróciło 17 wyników.
- Wyniki wyszukiwania podzielone są na poszczególne bazy. Dodatkowo przeglądy systematyczne dzielą się na Reviews oraz Protocols. Publikacje oznaczone ikonką Protocols są jeszcze w trakcie opracowania, ale możliwe jest zapoznanie się z wersjami wstępnymi.
- Pozostałe ikonki zawierają dodatkowe informacje o publikacji, odnoszące się m.in. do zmian w treści. Dla przykładu: NS (New Search) oznacza, że publikację zaktualizowano na podstawie przeprowadzonego od nowa przeglądu literatury, a CC (Conclusions Changed) informuje o istotnej zmianie wprowadzonej do części zawierającej wnioski. Po najechaniu kursorem na każdą z ikonek pojawia się podpowiedź dotycząca jej znaczenia.
Wyszukiwanie zaawansowane w The Cochrane Library
Złożone wyszukiwanie wymaga korzystania z Search Managera. Sposób jego obsługi różni się trochę od sposobu użycia narzędzi wyszukiwawczych przedstawionych wcześniej. Należy wpisać każdą szukaną frazę w osobnym, ponumerowanym wierszu, a następnie połączyć wszystkie frazy w całość, wykorzystując operatory logiczne. Każde pole umożliwia bezpośrednie odwołanie się do słownika MeSH w celu wstawienia hasła do Search Managera.
Przykładowy problem: Potrzeba znaleźć przegląd systematyczny dotyczący leczenia lekoopornej gruźlicy – bez udziału wirusa HIV. Do rozwiązania tego problemu sprawdzi się słownik MeSH.

Hasło przedmiotowe trzeba wstawić do wiersza przy użyciu ikony M (Insert a MeSH term into this row). Wybór tego polecenia powoduje przejście do słownika haseł przedmiotowych, zawierającego wyszukiwarkę terminów oraz informacje o potencjalnej liczbie wyników wyszukiwania. Po wybraniu odpowiedniego hasła należy umieścić je w wierszu za pomocą polecenia Update Search Manager.
- Każde hasło stanowiące element zapytania wyszukiwawczego znalazło się w osobnym, numerowanym wierszu (#1, #2, #3). Wiersz #4 zawiera część wspólną dla haseł wpisanych w wierszach #1 i #2. Do wybrania części wspólnej tych dwóch zbiorów posłużył operator logiczny AND.
- Przykład pokazuje, że część wspólna dla zbiorów odpowiadających zapytaniom tuberculosis oraz drug resistance to 155 publikacji. Warto zauważyć, że podana liczba dotyczy prac zgromadzonych we wszystkich siedmiu bazach, więc przeglądy systematyczne stanowią zaledwie część otrzymanej listy.
- Po wciśnięciu przycisku GO wiersz #5 będzie zawierał zbiór publikacji z wiersza #4, z którego – za pomocą operatora logicznego NOT – wykluczone zostaną publikacje dotyczące wirusa HIV (wyszukiwanie dla niego przeprowadzono w wierszu #3).